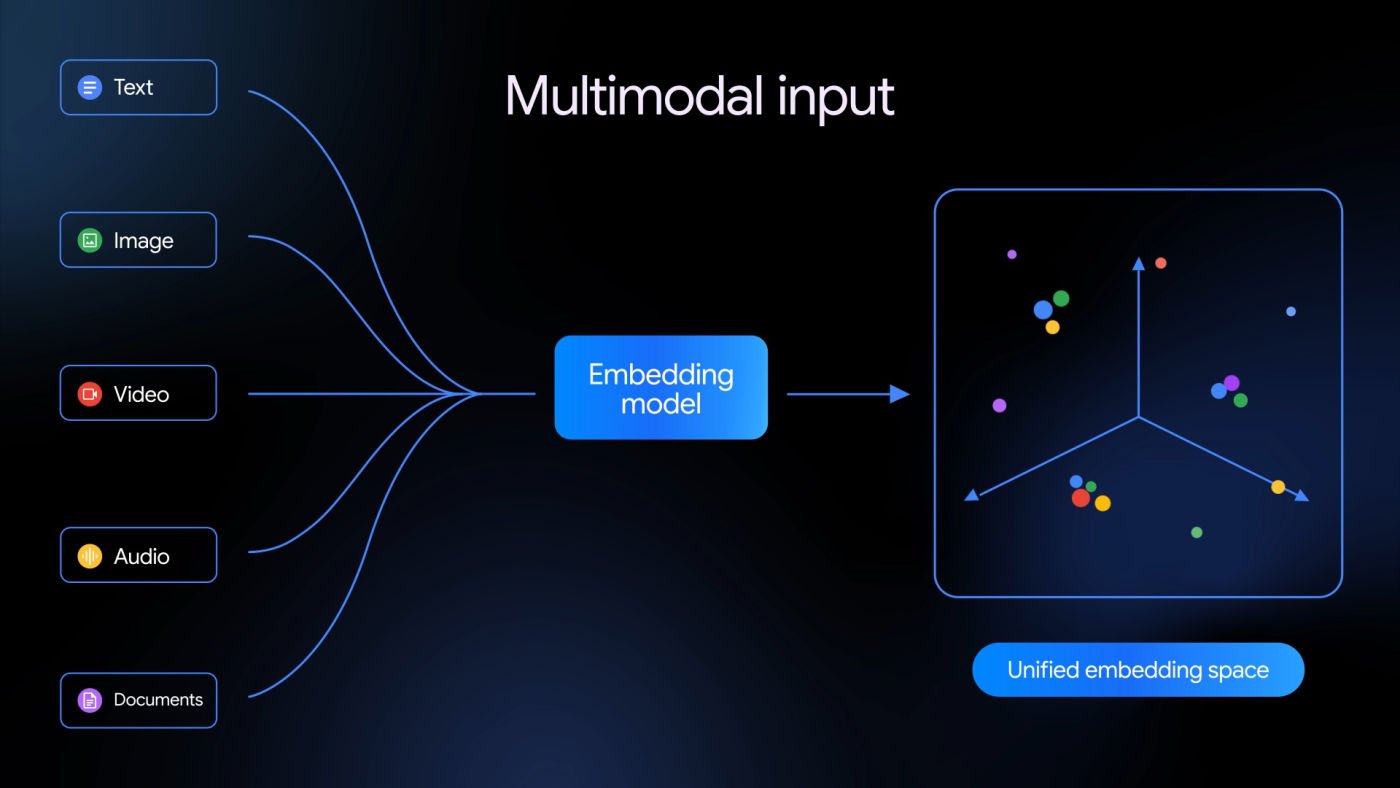
Google révélé Gemini Embedding 2, son premier modèle d’intégration d’IA nativement multimodal. Contrairement aux modèles génératifs comme Gemini 3, un modèle d’intégration ne produit pas de contenu : il convertit différents éléments (texte, image, vidéo, audio) en vecteurs mathématiques qu’une machine peut analyser pour comprendre la signification et les relations entre les données.

Une architecture unifiée qui simplifie les tâches
La première génération du modèle était limitée au texte. Gemini Embedding 2 intègre désormais cinq éléments dans un espace vectoriel unifié, avec prise en charge de 100 langues
Les limites par élément sont les suivantes :
- Texte : jusqu’à 8 192 jetons par requête
- Images : jusqu’à six images par demande (PNG/JPEG)
- Vidéo : jusqu’à 120 secondes en MP4/MOV
- Audio : ingestion directe sans transcription intermédiaire
- Documents : PDF jusqu’à six pages
Le principal intérêt réside dans la possibilité de combiner plusieurs éléments dans une seule requête, par exemple une image accompagnée de texte, pour capturer les relations sémantiques entre différents types de médias. Google indique que le modèle « simplifie l’accès complexe et améliore une grande variété de tâches multimodales en aval, depuis la génération augmentée de récupération (RAG) et la recherche sémantique jusqu’à l’analyse des sentiments et le regroupement de données ».
Sur le plan pratique, Google cite l’exemple des professionnels du droit : dans le cadre de procédures de divulgation de litiges, les intégrations multimodales de Gemini ont amélioré la précision et le rappel sur des millions de documents, tout en renforçant la recherche d’images et de vidéos.
Gemini Embedding 2 est disponible dès maintenant via l’API Gemini et Vertex AI sous la référence gemini-embedding-2-preview. Le modèle précédent, gemini-embedding-001, reste accessible pour les cas d’utilisation de texte uniquement.


